MySQLデータベース
目次
AccessからSQLデータベースへの乗換え
割と使いやすく、入門や小規模の管理にはピッタリのAccessですが、業務で使用する規模が大きくなると「弱点」がいろろ見えてきます。
Accessに弱点とは?
「Accessには弱点がある」
といきなり書いてしまうと、その技術を持っているのを前記事でセールスポイントのように書いたのに何だ! と叱られそうですが、なにが弱点なのかについて詳しくご説明すると納得して頂けると思います。
Accessの弱点は、データベースのファイルサイズに2GBまでという上限がある事です。
なぜファイルサイズの上限が弱点になるのか?
少々長いですが、データベースを扱う技術者の笑い話にこんなのがあります。
「1 ~ 4,294,967,295 までしかインクリメントしないから、仮にもし「1 日 100 万レコード」ずつ INSERT されたら 11 年と 9 ヶ月ちょっと経つと duplicate key が発生してしまう!!」
http://blog.livedoor.jp/nipotan/archives/7100625.htmlからの引用させていただきました。
なぜこれが笑い話なのか判らない方が多いと思いますので、ジョークを真面目に解説するのは野暮天の極みなのですが、あえて解説します。
Accessももちろんそうですが、 データベースにはそのレコードにしか存在しない、ユニークキーが必要です。
「ユニーク」は、日本語の中では「おもしろい」という意味に取られがちですが、技術的には「唯一の」を意味します。
データベースの場合、蓄積したデータの1行をレコードといいますが、他のレコードには絶対に含まれず、たった一つ、そのレコードだけに唯一含まれる情報が必要なのです。
これを実現しようとすると、一番簡単なのが通し番号をふる事です。
インクリメントとは、データ挿入時に自動で増える番号情報を持たせる機能で、言ってみれば通し番号製造機能です。
空の状態のデータベースに、インクリメントを仕掛けて、100件のデータを投入すると、番号情報に1~100が自動で割り当てられ、その次に100件投入すると、101~200というように、順序よく値が増えていきます。
では登録後、50~75の25件を削除したらどうなるでしょう? 実は再利用はされません。本当に、そのレコードがINSERTされるときに振られる、そのレコードの為だけの唯一の番号なのです。
しかし、このオートインクリメントを格納するデータの型には上限の値があって、 記載の通り、4,294,967,295 が最大の値となります。
つまり、1日に100万件のデータをデータベースに投入し続けると、毎日100万の番号が増え続けますので、4295日目の100万件を投入しようとすると、途中でインクリメントの数が上限値に達したというduplicate keyエラーを起こして止まります。
こうなると、もう新たなデータは投入できません。
完全にお手上げになってしまいます。
ですが、4295日、つまり約12年も、コンピュータがどこも故障せずに動き続ける事は、まずありえません。
必ずどこかトラブルが起き、結果、新しいコンピュータに更新(リプレースとも言います)が検討され、古いデータの削除や、大きなテーブルは分割が提案されて…と手が打たれます。
そう!上の笑い話は、まず起きない事を大げさに怖がって見せる、「まんじゅう恐い」のようなジョークだった、という訳なのです。
そして、このオートインクリメントを格納するためには、1件のレコードにつき、4バイトというデータ量を必要とします。
つまり、4,294,967,295件を格納するには、計算上、約16GBが必要となり、Accessの上限値の2GBを大きく超えてしまいます。
ましてインクリメントの値だけ並んでいても意味がないので、Accessは大量のデータを格納できないという事になります。
また、Accessでは、テーブルや、クエリ、フォーム、モジュールなどの全ての情報が、一つのファイルの中にすべて納められるという弱点もあります。
ただでさえ、上限があるのに、テーブル以外も格納されるため、さらにデータ量が少なくなります。
目安としては、体験上ですが、Accessの場合、10万件を超えるデータは扱わない方がよいです。
さらに、すべての情報が一つのファイルの中のため、多数のコンピュータからデータを要求されると、ファイルが破損する事があります。
目安としては、こちらも体験上ですが10台を超えるパソコンで、同時にAccessのデータに接続する事は避けた方が良いです。
大量のデータは格納できないわ、複数から接続すると壊れるわでは、弱点があるどころか、欠陥ソフトと思われてしまうかもしれません。
とんでもない!Accessはそうした弱点を補って余り在る優秀なデータベースです。
なんといっても、ユーザーインターフェイスが他のデータベースに比べ、圧倒的に優秀です。
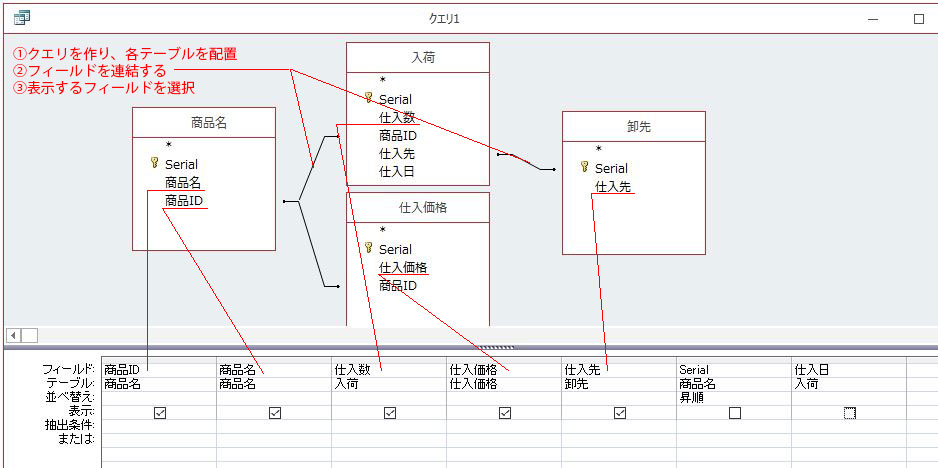
テーブル間を視覚的に連結して、データを取り出すクエリを作成でき、かつ、そのクエリをSQLで取り出せるので、SQL作成が非常に効率的に行えます。
また、VBA( Visual Basic for Applications )内蔵で、かなりのアプリをAccess単体で作成できます。
ファイルが一つになってしまうというのは欠点でもありますが、規模のあまり大きくないアプリなら、このファイル一つでデータから操作系まですべて内包できますから、ファイル一つバックアップするだけで、全てが保護できるという利点でもあります。
そもそも論として、先のデータベース技術者の笑い話ではないですが、43億件に近いレコードを投入したり、それを検索したりすることそのものが、普通の会社のデータベースではまずありません。
10万件以内くらいのデータ量でしたら、Accessは充分な能力を発揮できます。
ですが、どうしても大きなデータを扱う必要が生じる事もあるでしょう。
2GBが上限では、そこはどうする事もできないように見えますが、実は、Accessはそれを突破する非常に優秀な機能を持っています。
他のデータベースをリアルタイムで取り込んでしまう、リンクテーブルという機能がそれです。
最初はAccess単体でスタートしたシステムが、データが多くなってきたら、データの部分だけ別のデータベースに格納してしまい、機能だけAccessのファイルに残すという離れ業ができるのです。
私も社内SEとして勤務するうち、最初はAccessで稼働していたシステムがデータ量が増えて負担になったため、データ部分だけSQLサーバー系のデータベースに移行した事が何度かあります。
その手順をご紹介したいと思います。
データベースサーバーを作る
まず、SQLサーバー系のデータベースサーバー機を用意します。
Microsoftの製品に、そのものズバリの名前のSQLServerという製品があって、混同してしまう事があるのですが、ここではSQL(Structured Query Language)での問い合わせが出来るデータベースの事で、Linux環境のデータベースでも問題ありません。
Windows Serverをインストールしたサーバー機を用意し、そこに SQLServerを導入する事も可能ですし、そのスキルもあるのですが、Windows ServerとSQLServerの組み合わせは、かなりの高額になりますので、ここでは無料で使用できるCentosと、MySQLの派生のMariaDBで進行します。
別記事の通り、サーバー用のコンピュータにCentOSをインストールして、「サーバー機」を用意します。
次に、mariadbのサイトに行き、リポジトリを入手します。
https://downloads.mariadb.org/mariadb/repositories/
1. Choose a Distro
でOSの種類を、
2. Choose a Release
で、OSのバージョンを
3. Choose a Version
でmariaDBのバージョンを選びます。
今回ですが、OSはCentOSを、バージョンはCentOS 6 (x86_64)を、mariaDBは、10.2を選択しました。
すると、
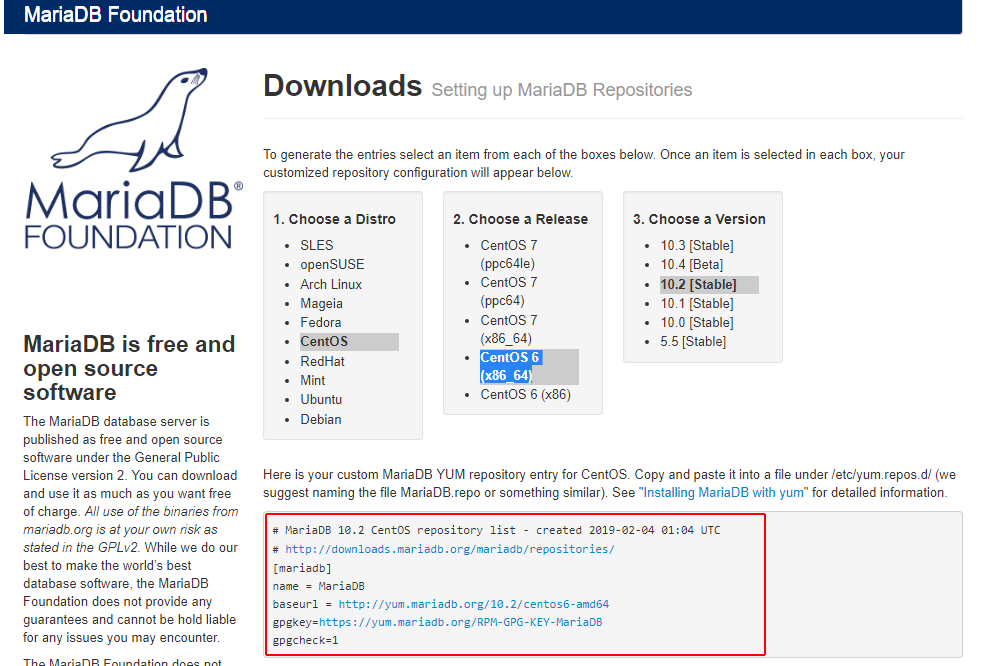
このように、リポジトリの情報が表示されます。ここでは赤枠で囲っていますが、実際には赤枠はありません。
この情報をコピーし、サーバー機のコンソールから
# vi /etc/yum.repos.d/MariaDB.repo
でファイルに文字列を挿入出来る状態にして、このリポジトリ情報を丸ごと貼り付けします。
# yum --disablerepo=\* --enablerepo='mariadb' list available
# yum --enablerepo='mariadb' install -y MariaDB-server
で、データベースがインストールできます。
MariaDB Serverがインストールできたので、起動します。
# /etc/init.d/mysql start
[ OK ]
# chkconfig mysqld on
起動できたら初期化します。
# mysql_secure_installation
途中、データベースのrootのパスワードを問われますが、それ以外はEnterでOKです。
# mysql -u root -p
Enter password:[先ほど設定したパスワード]
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
+--------------------+
3 rows in set (0.00 sec)
コマンドと、パスワードを入力すると、MariaDB [(none)]> というプロンプトが現れます。
ここにSQLコマンドを入力すると、結果が返ってきます。
上記では、show databases; データベース一覧を表示せよ という命令文を入力し、結果が表示されます。
これでAccessのユーザーインターフェイスが他より優秀と言った意味がお判りかと思います。
データの格納元の表示もコマンドで、もちろん、視覚的に結合する事はできません。これでは判りにくいと思われても仕方ないと思います。
MariaDB [(none)]> create database `vegetables`;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> use `vegetables`
Database changed
MariaDB [vegetables]> CREATE TABLE `wholesale` (
-> `serial` INT AUTO_INCREMENT
-> ,`仕入先` TINYTEXT
-> ,INDEX(`serial`)
-> );
Query OK, 0 rows affected (0.19 sec)
MariaDB [vegetables]> show columns from`wholesale`;
+-----------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+----------+------+-----+---------+----------------+
| serial | int(11) | NO | MUL | NULL | auto_increment |
| 仕入先 | tinytext | YES | | NULL | |
+-----------+----------+------+-----+---------+----------------+
MariaDB [vegetables]> INSERT INTO `wholesale` (`仕入先`) VALUES ('鈴木屋');
Query OK, 1 row affected (0.05 sec)
MariaDB [vegetables]> INSERT INTO `wholesale` (`仕入先`) VALUES ('佐藤青果');
Query OK, 1 row affected (0.04 sec)
MariaDB [vegetables]> select * from `wholesale`;
+--------+--------------+
| serial | 仕入先 |
+--------+--------------+
| 1 | 鈴木屋 |
| 2 | 佐藤青果 |
+--------+--------------+
2 rows in set (0.00 sec)
MariaDB [vegetables]> CREATE USER 'user01' IDENTIFIED BY 'ghcrxw7k';
Query OK, 0 rows affected (0.000 sec)
MariaDB [vegetables]> GRANT SELECT,UPDATE,INSERT,DELETE ON `vegetables`.* TO 'user01';
Query OK, 0 rows affected (0.000 sec)
データベースを作成し、そのデータベースにテーブルを加え、そのテーブルに2件のデータを追加するだけで、これだけのコマンドを入力する必要があります。
ちなみに、最後の2行は、データベースのユーザーを追加しています。
マウスで操作して、そのままデータを入れるだけのAccessに比べると、操作性の差は否めませんが、これはこれで、何をしているのがはっきり判るため、私はこちらも使えるようにしています。
ODBCのインストール
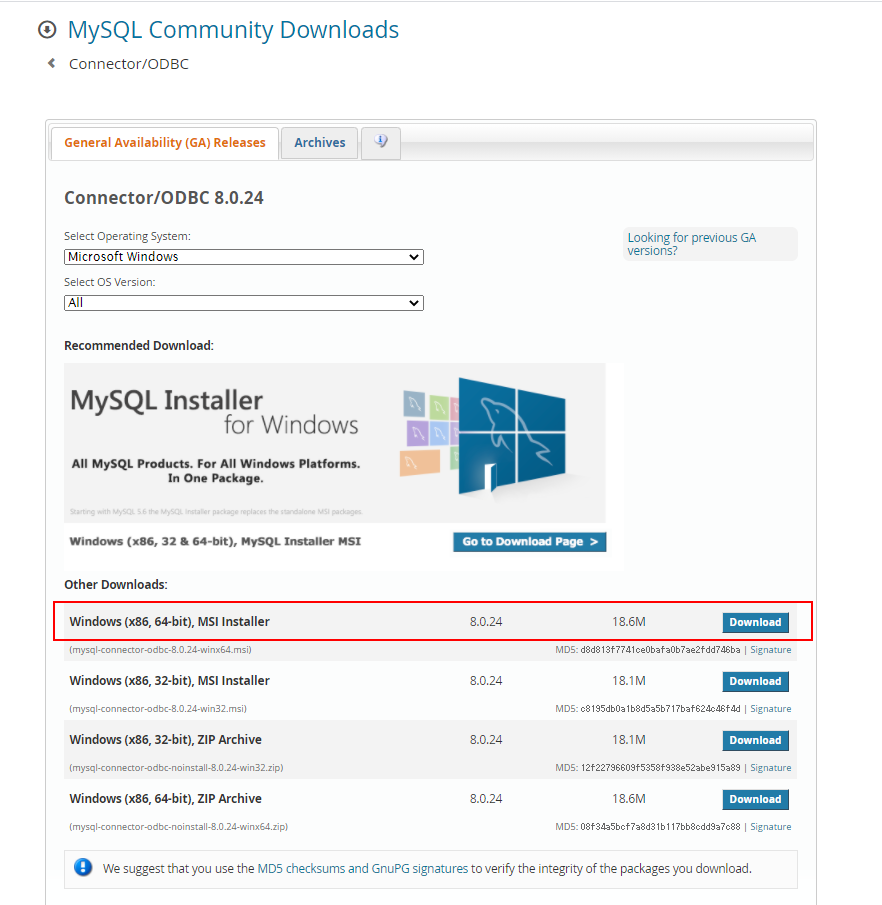
MySQLの場合ODBCを使用するには、ODBCドライバーをインストールする必要があります。
ODBCドラバーは、こちらのサイトからダウンロードする事ができます。
Windows10の場合は、64bit用ですね。
mysql-connector-odbc-3.51.**はOracleの提供なので、アカウントを求められます。
Oracleのアカウントを持っていない場合は、取得しておいた方が良いでしょう。
DSNの設定
ドライバがインストールできたら、DSNを作成します。
Windows10 の場合、スタートの横の検索に、ODBCと入力すると、データソースのセットアップが出ます。
32bitの方を起動します。
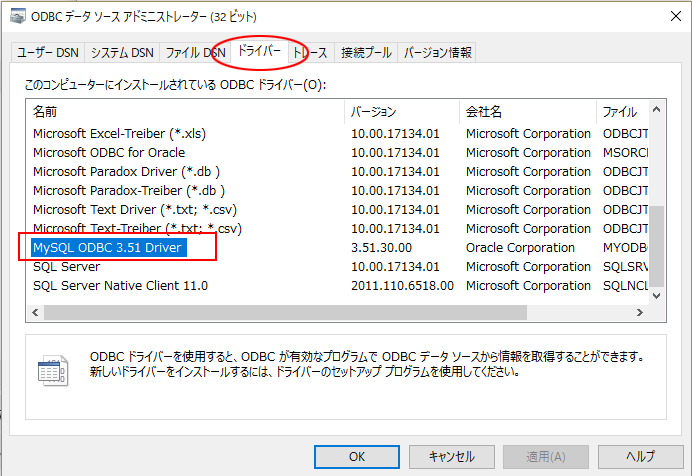
インストールが正常だと、このように MySQL ODBC 3.51 Driver が表示されています。
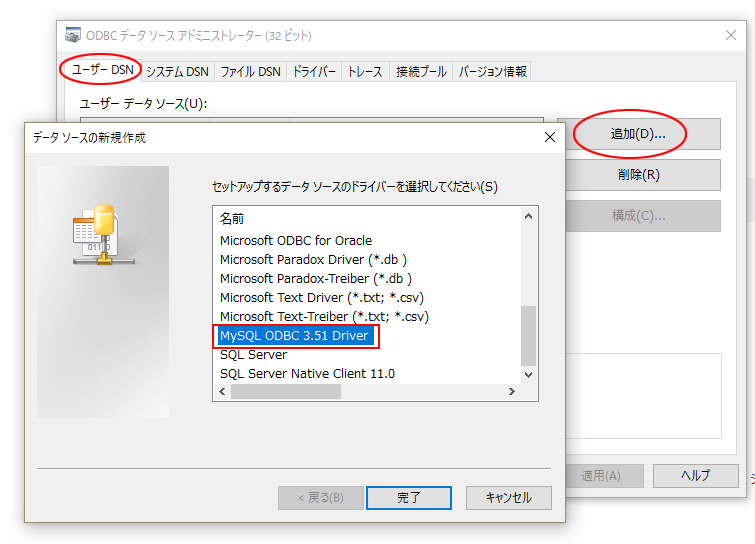
ユーザーDNSのタブを選び、追加ボタンを押すと、ドライバーの選択画面になるので、先ほどの MySQL ODBC 3.51 Driver を選びます。
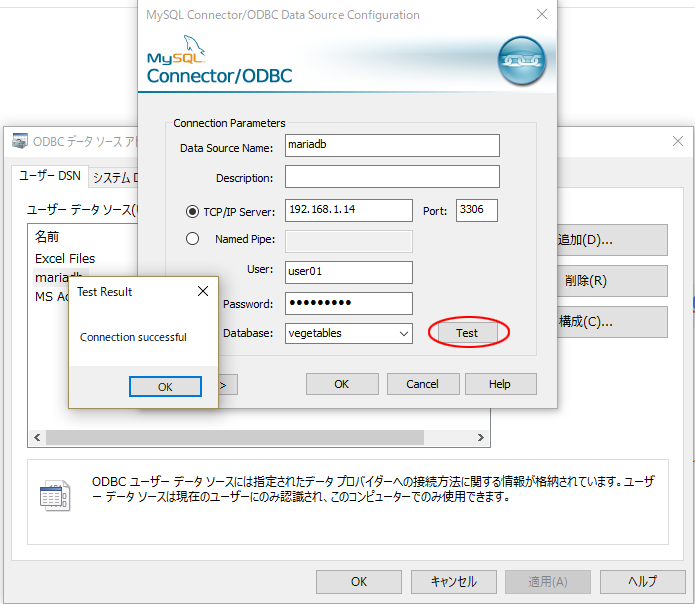
Data Source Name は自分の判りやすい名前をつけます。
TCP/IP Server は、ここではデータベースサーバーのIPアドレスになっています。
userとpasswordは、先ほどコマンドで追加したものを入ルよくします。
これにより、Testボタンをクリックすると、接続が試行され、OKならこのようにダイアログがでます。
データベースを、作成したデータベース名に合わせておきましょう。
ODBCでデータをリンクする
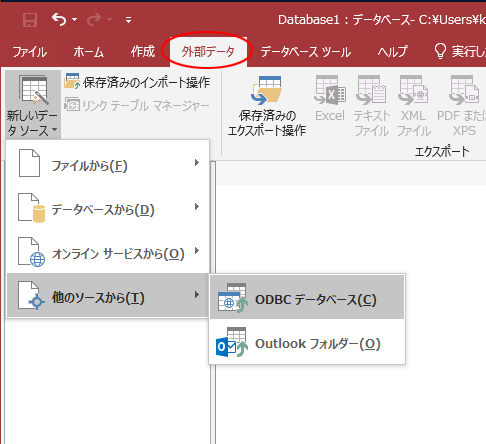
Accessで、外部データから、ODBCデータベースを選びます。
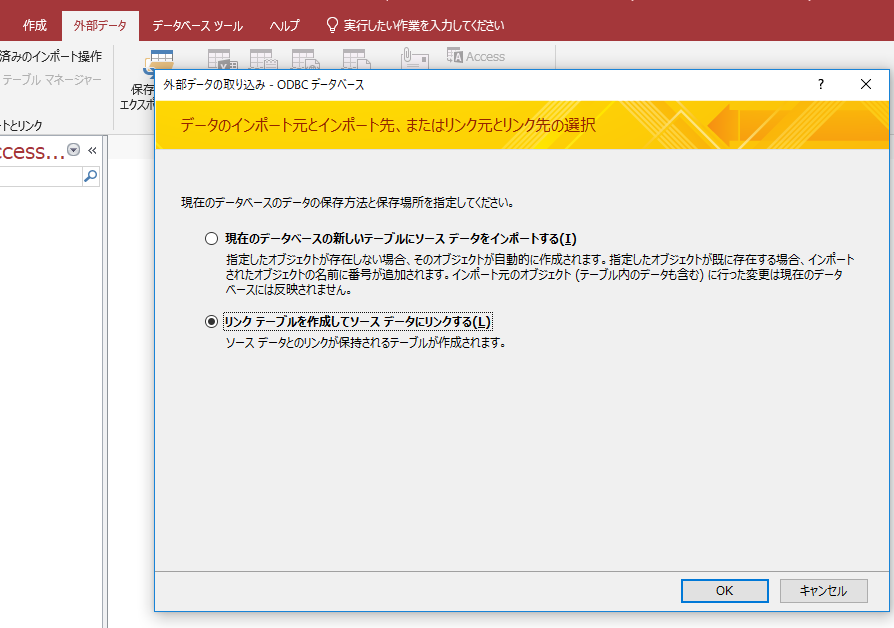
リンクテーブルを作成して を選びます。インポートで取り込む事もできますが、それではデータを外部から参照するという利点がなくなってしまいます。ただ、元になるデータベースのデータを修正したいときなどは、使いようがあります。
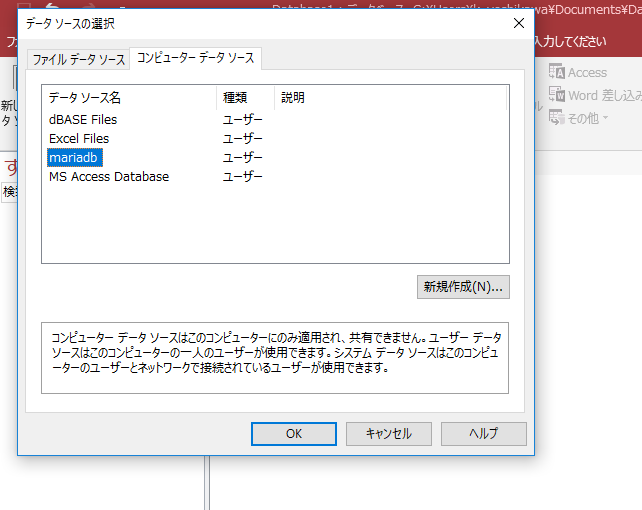
コンピュータデータソースで、先ほど設定した Data Source Name が表示されいるはずですので、それを選択します。
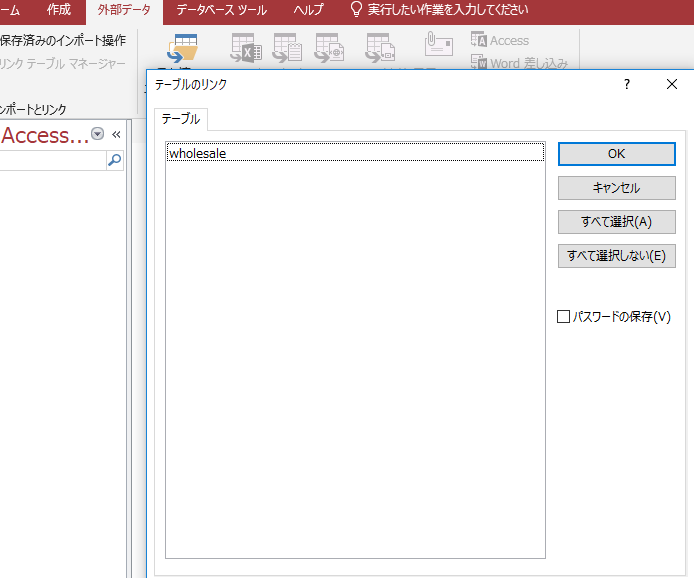
CREATE TABLE wholesale と作成した、wholesale が表示されています。
もちろん、本格業務データベースともなると、テーブル数が100を超えるのも珍しくありません。
テーブル名を選択して、OKをクリックします。
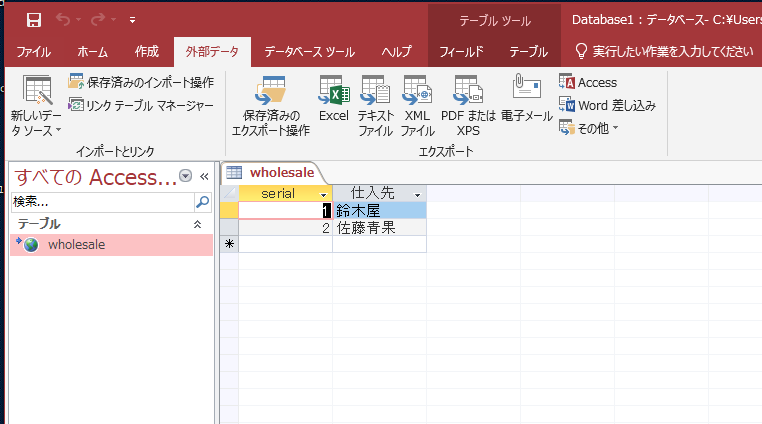
テーブルのところに、データベースサーバーのテーブル名が、地球のようなマークとともに表示されています。
内容は、先ほどコマンドで登録した通りになっています。
これで、このwholesaleテーブルは、Accessのテーブルとして使用することができ、クエリなどで自由に加工が可能です。
また、例えば何か別の自動プログラムなどで、データベースサーバーの
wholesaleテーブル にデータを追加したりしても、クエリなどで参照した時点で最新のデータが表示されます。
これでデータ本体はデータベースサーバーに預け、それこそ場合によっては、42億件のデータを扱う事も可能ではあります。
※無論、メモリは消費しますので、実際にそれだけの件数をAccessで読み込むには、よほど速くメモリも豊富なパソコンとサーバー機が必要です
なお、今回は端折りましたが、データベースの文字コードと、Accessで使用するsjisコードの変換がうまく行かないと、
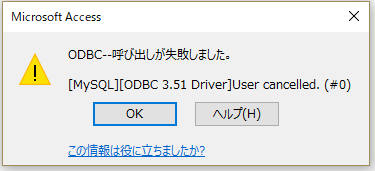
と、接続ができなかったり、接続できても開けない、日本語が意味不明の文字列になる文字化けをしている などの状態になる事があります。
そのときは、
ここで拡張設定を開き、文字コードを指定します。
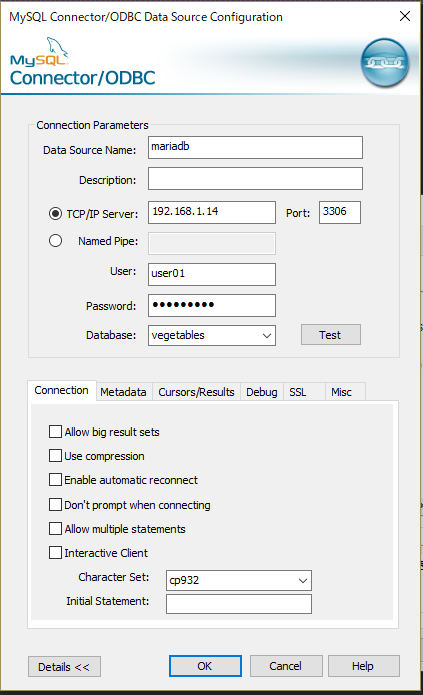
今回のシステム構成では、データベースサーバーがutf8で稼働しているため、CP932を指定すると、うまく日本語処理ができました。
データベースサーバーは、場合により、文字コードが違う事があるので、その場合にはcp932の部分を別コードにして、文字化けしないよう調整します。
このように、データベースサーバーを構築して、それをAccessをはじめとする他のアプリから呼び出す事で、売上データを集計したり、商品の情報を蓄積したりなど、様々な処理に使用する事ができます。
これらのスキルは、きっと御社のお役に立つと思います。

