Pythonでデータベースを操作
Pythonからデータベースに書き込み
WEBサイトの自動巡回(スクレイピング)の例の様に、Pythonはコードが判りやすいのが特徴です。
例えば VBAでは、
Sub test01()
Dim i As Integer
For i = 0 To 9 Step 1
Debug.Print i
Next
End Sub

と、インデントもなにも取らず、ただ列記しただけで動きます。
しかし、これが業務用のVBAアプリだったりすれば、100行、場合によっては数百行ですから、追いかけるのが大変です。
一方、Pythonで同じようにインデント無しをしようとするとエラーになります。
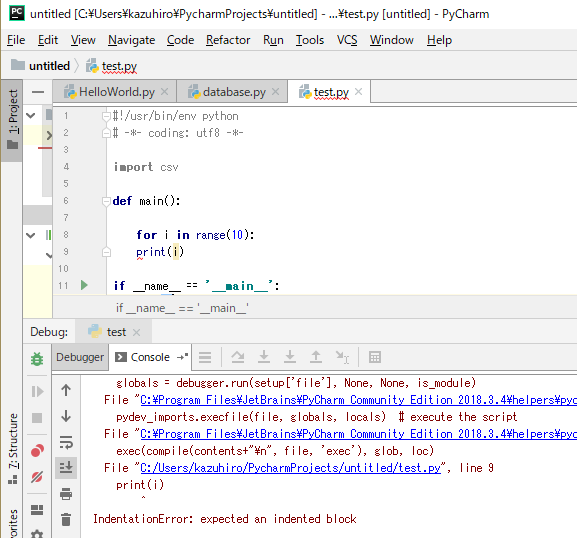
VBAではForの終了はNextですが、Pythonでは終了が無く、インデントが取られているところがForの中とされるためです。
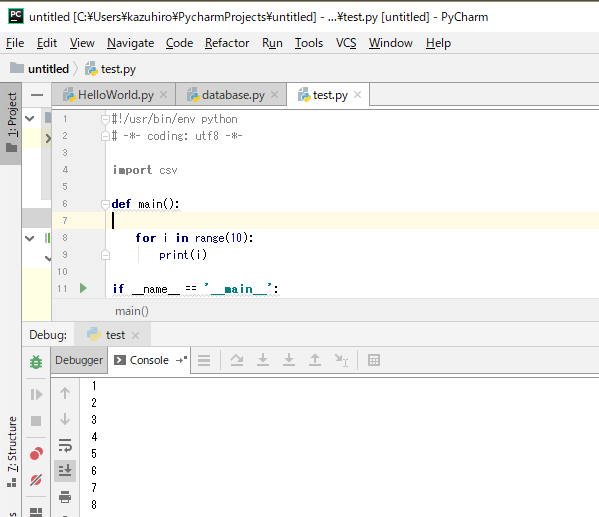
インデントを取ると正常に動きます。
Windowsなどの画面上のアプリを作成するのは、少々手がかかります。
このため、私の社内SEとしての開発では、pytonはデータの書き込みがメインになっていました。
一度、Excelを制御して、VBAの代わりにデータをシートに書き込むプログラムは作成した事があるのですが、自分のスキルだと公開してしまうのも守秘の関係から問題があるので、データINSERTをメインにします。
早速ですが、日本郵便のダウンロードページから、郵便番号のCSVデータを取得します。
とりあえず、居住地の千葉県にしました。
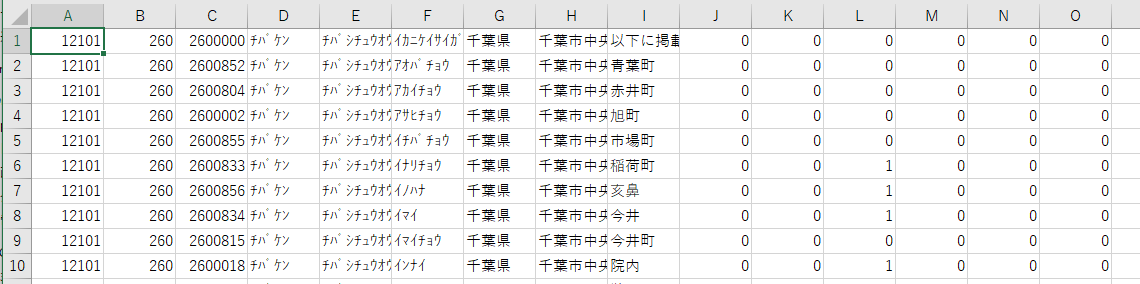
これをデータベースに取り込むことにします。
pythonでmysql系のデータベースを扱うには、mysql-connector-pythonが必要です。
pip install mysql-connector-python
ですが、私の環境はAnacondaなので、conda でインストールします。
(base) c:\Anaconda3>conda install mysql-connector-python
Solving environment: done
## Package Plan ##
environment location: C:\Anaconda3
added / updated specs:
- mysql-connector-python
The following packages will be downloaded:
package | build
---------------------------|-----------------
protobuf-3.6.0 | py37he025d50_0 516 KB
mysql-connector-c-6.1.11 | h33f27b4_0 4.8 MB
mysql-connector-python-8.0.13| py37h13ed8b8_0 566 KB
libprotobuf-3.6.0 | h1a1b453_0 1.7 MB
conda-4.6.2 | py37_0 1.7 MB
------------------------------------------------------------
Total: 9.3 MB
The following NEW packages will be INSTALLED:
libprotobuf: 3.6.0-h1a1b453_0
mysql-connector-c: 6.1.11-h33f27b4_0
mysql-connector-python: 8.0.13-py37h13ed8b8_0
protobuf: 3.6.0-py37he025d50_0
The following packages will be UPDATED:
conda: 4.5.12-py37_0 --> 4.6.2-py37_0
Proceed ([y]/n)? y
Downloading and Extracting Packages
protobuf-3.6.0 | 516 KB | ############################################################################ | 100%
mysql-connector-c-6. | 4.8 MB | ############################################################################ | 100%
mysql-connector-pyth | 566 KB | ############################################################################ | 100%
libprotobuf-3.6.0 | 1.7 MB | ############################################################################ | 100%
conda-4.6.2 | 1.7 MB | ############################################################################ | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
SQLデータベース の記事で作成したデータベースに、郵便番号用のテーブルを用意します。
テーブルの各項目については、郵便番号データの説明ページを参照しました。
このように、CSVデータなど、決まったカタチのデータを納める場合は、そのデータに合わせてテーブルを作成します。
CREATE TABLE `postal_code` (
`serial` INT UNSIGNED AUTO_INCREMENT
,`団体コード` MEDIUMINT UNSIGNED
,`番号5桁` MEDIUMINT UNSIGNED
,`番号7桁` MEDIUMINT UNSIGNED
,`都道府県名カナ` TINYTEXT
,`市区町村名カナ` TINYTEXT
,`町域名カナ` TINYTEXT
,`都道府県名` TINYTEXT
,`市区町村名` TINYTEXT
,`町域名` TINYTEXT
,`caution01` TINYINT UNSIGNED
,`caution02` TINYINT UNSIGNED
,`caution03` TINYINT UNSIGNED
,`caution04` TINYINT UNSIGNED
,`caution05` TINYINT UNSIGNED
,`caution06` TINYINT UNSIGNED
,INDEX(`serial`)
);
では、Pythonにコードを作成します。
今回の場合は、データベースに接続し、Pythonの実行ファイルのpyと同じ場所のCSVを探して、それを読み込んでいます。
SQLでデータ登録(INSERT)をする場合、文字列は ’ (シングルクォート)で囲み、数値は囲まないので、どのフィールドが文字列か、もしくは数値かを、リストで与え、CSVの一番左のカラムを0として、このリストで判断させています。
#!/usr/bin/env python
# -*- coding: utf8 -*-
import os
import csv
import mysql.connector
con = mysql.connector.connect(
host='centos6101',
db='vegetables',
user='user01',
password='upassword'
)
path = r'./'
def filecheck():
# csvファイルを探す
files = []
texts = []
for x in os.listdir(path):
if os.path.isfile(path + x):
files.append(x)
for y in files:
if (y[-4:] == '.CSV'): # ファイル名の後ろ4文字を取り出してそれが.csvなら
texts.append(y) # リストに追加
flnm = texts[0]
#CSVのフィールドの形式
stri =[3,4,5,6,7,8]
numb =[0,1,2,9,10,11,12,13,14]
intbn = 'postal_code'
csvdata(flnm,stri,numb,intbn)
def csvdata(csf,stri,numb,intbn):
#データベース接続
cur = con.cursor(buffered=True)
#使用CSVを確定。
filename = path + csf
f = open(filename, 'r', encoding='shift_jis')
reader = csv.reader(f)
sqlh = 'INSERT INTO `' + intbn + '` ('
sqlh += ' `団体コード`'
sqlh += ', `番号5桁`'
sqlh += ', `番号7桁`'
sqlh += ', `都道府県名カナ`'
sqlh += ', `市区町村名カナ`'
sqlh += ', `町域名カナ`'
sqlh += ', `都道府県名`'
sqlh += ', `市区町村名`'
sqlh += ', `町域名`'
sqlh += ', `caution01`'
sqlh += ', `caution02`'
sqlh += ', `caution03`'
sqlh += ', `caution04`'
sqlh += ', `caution05`'
sqlh += ', `caution06`'
sqlh +=") VALUES "
data = []
for row in reader:
data.append(row)
sql = ''
i = 0
for row in data:
sql += "("
n = 0
for el in row:
if el == '':
sql += "NULL"
elif el != '':
if n in stri:
sql += "'"
sql += el
sql += "'"
elif n in numb:
sql += el
sql += ","
n+=1
i +=1
if i==100:
sql = sql[:-1]
sql +=");"
sql = sqlh + sql
cur.execute(sql)
con.commit()
i=0
sql=""
elif i != 100:
sql = sql[:-1]
sql += "),"
if sql != '':
sql = sql[:-2]
sql += ");"
sql = sqlh + sql
cur.execute(sql)
con.commit()
sql = ''
f.close()
# カーソル終了
cur.close()
def main():
filecheck()
if __name__ == '__main__':
main()
CSVファイルは、1行目がカラムリストである場合と、1行目からデータの場合があります。
JPのデータは1行目からデータなので、今回の例では、プログラム中にデータベースのフィールド名が記載してあります。
一方、1行目がカラム名のCSVデータを取り込む場合は、データベースの設計をカラム名と合致させておけば、1行目のデータを使用する事が可能です。
reader = csv.reader(f)
header = next(reader)
sqlh = 'INSERT INTO `' + intbn + '_newest` ('
fldl = ''
for row in header:
data.append(row)
for row in data:
fldl += "`"
fldl +=row
fldl += "`,"
fldl = fldl[:-1]
sqlh +=fldl
sqlh +=") VALUES "
sqlhの部分をこのように書くと、CSVの1行目をheader に取り込み、 header を分解して、シングルクォートを付け、SQLのヘッダにしています。
その後、2行目以降のデータを読み込み、判断リストを元に、文字列、数値で分けてSQLを構成していきます。
1行ごとにINSERT文を発行するのは、Serverにも負担ですので、100行データを貯めるごとにデータベースに渡しています。
もし、CSVには載っているけれど、データベースには登録不要のフィールドが在った場合は、除外リストを増やせば可能です。
逆にCSVに無い項目とデータを追加する事も可能です。
実務でこれを使用していた時は、テーブルにタイムスタンプ型のフィールドを一つ設け、CSVのファイル日時をそこに与えるといった事もしていました。
filename = [CSVファイルを指定]
fdt = datetime.datetime.fromtimestamp(os.stat(filename).st_mtime)
ftsmp = fdt.strftime('%Y-%m-%d %H:%M:%S')
sql = 'INSERT INTO `' + intbn + '` (`CSV作成日時`,'
sql += fldl
sql += ') SELECT \''
sql += ftsmp
sql += '\' AS `CSV作成日時`,'
sql += fldl
sql += ' From `' + intbn + '_temp`'
sql += ';'
cur.execute(sql)
一度、CSVそのもののデータを、_tempのついたテーブルに登録し、その後、その全データにCSVの日時を加えてINSERTするという構文です。
これにより、毎日変化するCSVの値を、日時で分類したテーブルに保存していました。
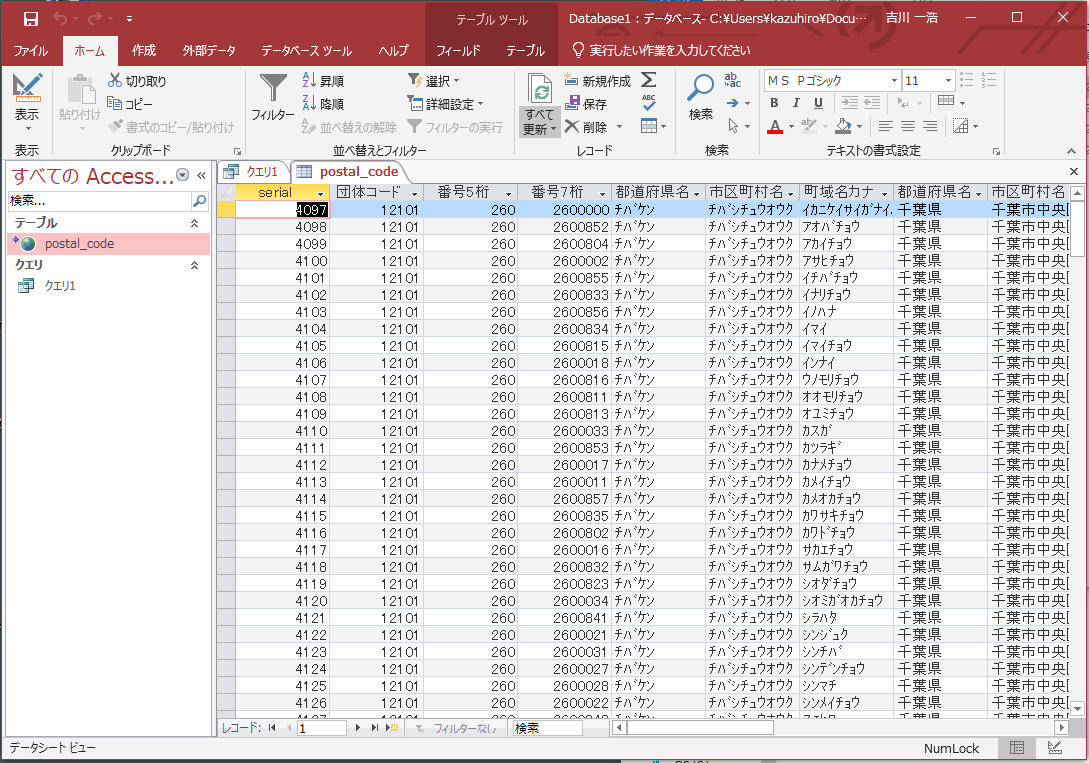
SQLサーバーのデータを、Accessにリンクしてみると、このようにcsvが取り込まれています。
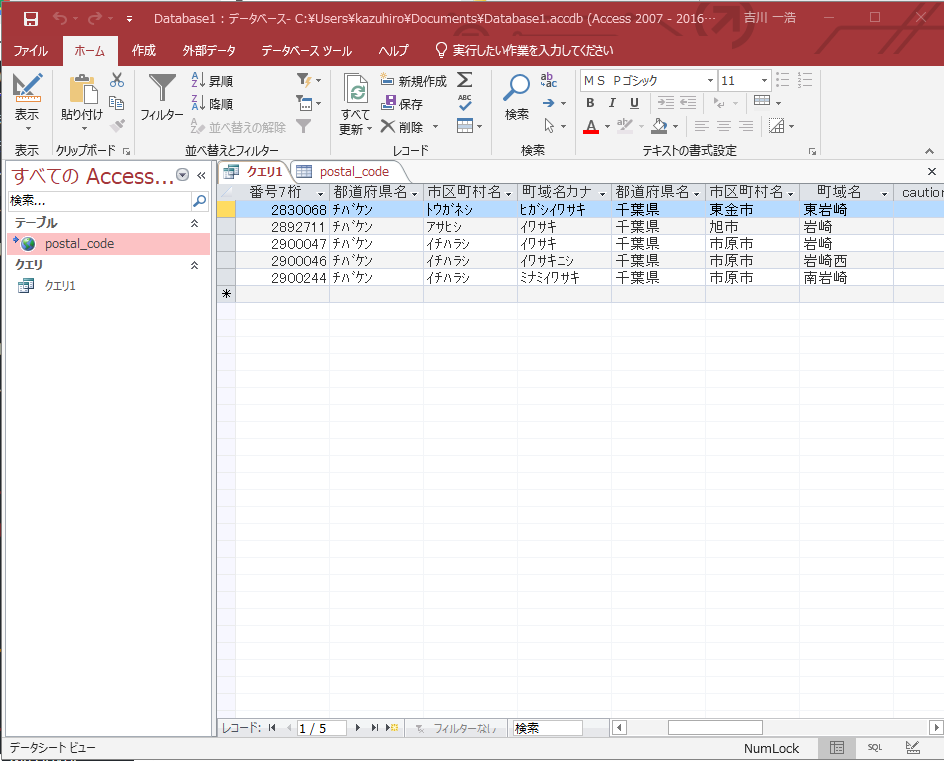
クエリで、町名に「岩崎」が入っているデータを検索すると、東金などいくつかのデータが出ました。
もし、郵便番号検索システムがほしいのであれば、あとはVBなどで、ウィンドウ表示のプログラムを作り、郵便番号や住所などで検索のSQLを組んでデータベースに投げるシステムを作れば、必要なものを作成することが可能です。
前職では、ブラウザの自動運転と組み合わせてプログラムし、そのpythonプログラムを、Windowsのタスクスケジューラで呼び出すことで、毎日、定時に目的のサイトに行ってCSVファイルをダウンロードし、そのCSVをデータベースに読み込むシステムを作成して使用していました。
このように、データベースを扱うスキルは、必ず御社のお役にたてると思います。
